



Si no sabes visualizar datos, básicamente estás a ciegas
Y no, no es una exageración. Es la cruda realidad.


Verás, los datos están por todas partes. En cada clic que haces, en cada compra que realizas, en cada "me gusta" que das en redes sociales (aunque lo hagas por compromiso). Los datos gobiernan el mundo. Pero hay una gran diferencia entre tener datos y entenderlos.
Si no los visualizas bien, te puedes pasar horas (o días) analizando números sin llegar a ninguna conclusión útil. Es como tratar de leer un libro en un idioma que no entiendes, esperando que, por arte de magia, la historia cobre sentido. No va a pasar.
Por eso, si trabajas con datos, ya sea porque eres analista, científico de datos, o simplemente alguien que quiere sacar conclusiones de una hoja de cálculo sin que le dé dolor de cabeza, debes aprender a visualizar la información correctamente.
Y para que no te pierdas en el abismo de los gráficos raros e innecesarios, aquí te dejo los 11 gráficos que realmente importan. Son los que se usan el 90% del tiempo en ciencia de datos. El resto son adornos.
1. KS Plot: ¿Son tus datos primos o completos desconocidos?
El KS (Kolmogorov-Smirnov) Plot no es solo un gráfico, sino un test para comparar dos distribuciones. Te dice cuánta distancia hay entre ellas y si pueden considerarse parte de la misma familia. Si crees que dos conjuntos de datos son similares pero el KS Plot dice que no… mejor confía en el gráfico.

2. SHAP Plot: ¿Qué variables realmente importan?
Si trabajas con modelos de machine learning y quieres saber qué factores influyen en las predicciones, el SHAP Plot es tu mejor amigo. No solo te dice qué variables pesan más, sino cómo lo hacen. Algo así como descubrir si el azúcar en tu café mejora o arruina el sabor.

3. ROC Curve: El dilema entre atrapar a los buenos y dejar escapar a los malos
Si estás entrenando un modelo de clasificación, no te puedes saltar esta gráfica. Te muestra el equilibrio entre el True Positive Rate (qué tan bien detectas lo que buscas) y el False Positive Rate (cuántas veces te equivocas). Ideal para decidir hasta qué punto confiar en tu modelo antes de que empiece a hacer locuras.

4. Precision-Recall Curve: El salvavidas de los datos desbalanceados
Cuando los datos están desbalanceados (por ejemplo, en un problema donde el 99% de los casos son negativos y solo el 1% es positivo), la curva ROC puede engañarte. En estos casos, es mejor usar la Precision-Recall Curve, que te ayuda a ver la relación entre precisión y cobertura sin distorsiones.

5. QQ Plot: ¿Siguen tus datos la distribución que crees?
¿Tus datos siguen una distribución normal o están haciendo lo que les da la gana? El QQ Plot (Quantile-Quantile Plot) los compara con una distribución teórica. Si los puntos caen en una línea recta, todo bien. Si no… tienes trabajo que hacer.

6. Cumulative Explained Variance Plot: Cuántas dimensiones necesitas en PCA
Cuando usas Análisis de Componentes Principales (PCA), necesitas decidir cuántas dimensiones mantener sin perder demasiada información. Este gráfico te muestra cuánta varianza explican las primeras componentes y te ayuda a elegir el número ideal de dimensiones.

7. Elbow Curve: ¿Cuántos clusters son los ideales en k-means?
Si usas k-means para agrupar datos, el Elbow Curve es crucial. Representa la suma de los errores al cuadrado frente al número de clusters. El punto donde la curva empieza a doblarse como un codo (de ahí el nombre) es donde deberías detenerte. Ni más, ni menos.

8. Silhouette Curve: Cuando el Elbow Curve no es suficiente
Si el Elbow Curve no te da una respuesta clara (o si tienes muchos clusters), usa la Silhouette Curve. Te ayuda a evaluar la cohesión dentro de los clusters y la separación entre ellos. Más confiable en datasets complejos.

9. Gini-Impurity y Entropy: Midiendo el caos en un árbol de decisión
Si trabajas con árboles de decisión, necesitas entender cuán desordenados están los datos en cada nodo. Estas dos métricas (Gini e Entropía) te ayudan a visualizar la pureza de cada división. La clave es minimizar la impureza para tomar mejores decisiones en la estructura del árbol.

10. Bias-Variance Tradeoff: El delicado equilibrio entre precisión y flexibilidad
El sesgo y la varianza son como dos fuerzas opuestas en machine learning. Un modelo muy simple (alto sesgo) no captura bien los datos. Uno demasiado complejo (alta varianza) se ajusta demasiado a los datos de entrenamiento y falla en generalizar. Este gráfico te ayuda a encontrar el punto medio ideal.

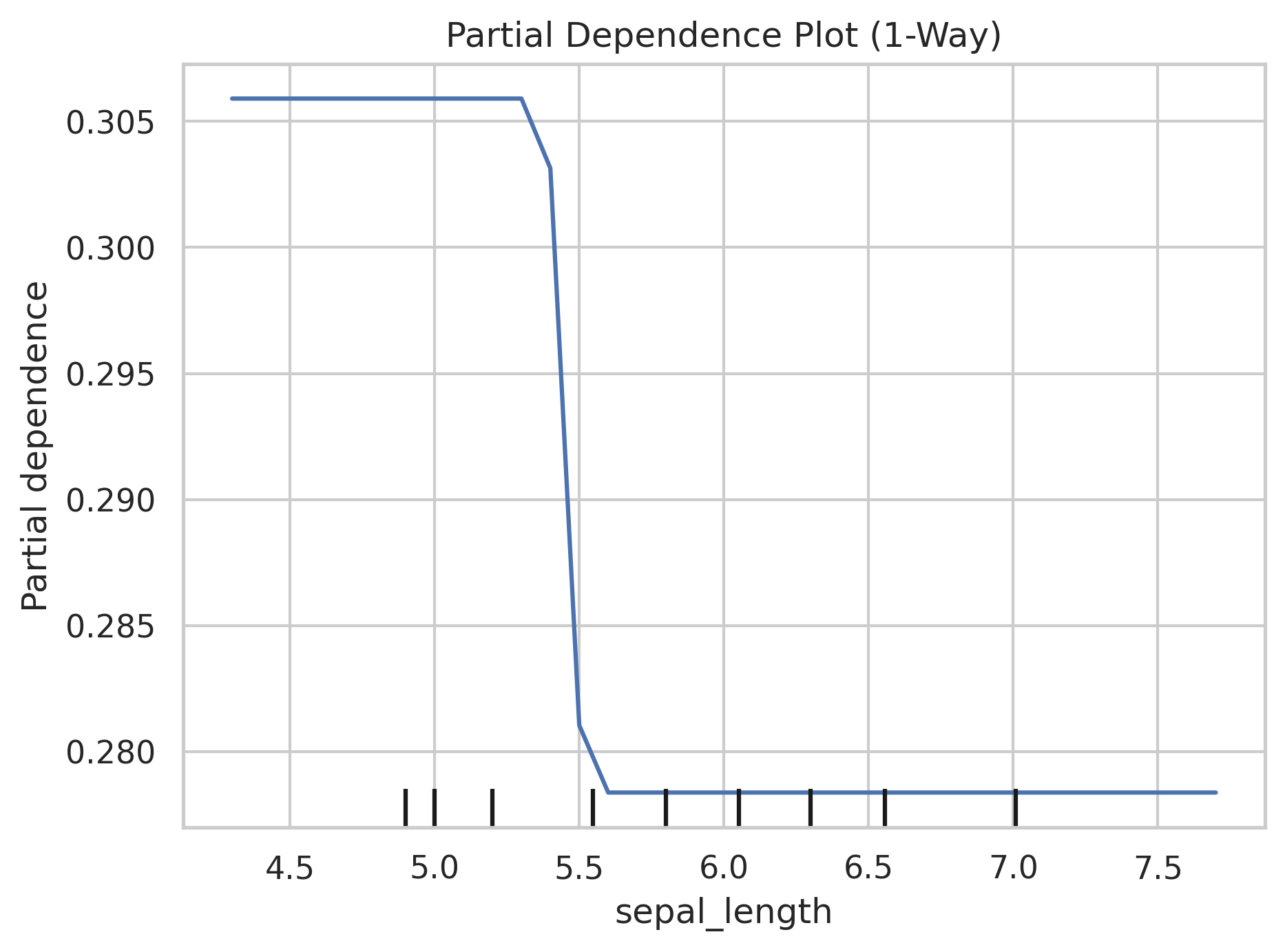
11. PDP (Partial Dependence Plot): La relación entre una variable y la predicción
Este gráfico muestra cómo cambia la predicción de tu modelo cuando alteras una variable específica. Es como hacer un experimento mental: "Si esta variable fuera diferente, ¿cómo afectaría el resultado?". Útil para entender la relación entre los datos sin tener que rehacer el modelo desde cero.

Si has llegado hasta aquí, significa que realmente te interesa el tema. O que simplemente te gusta ver gráficos bonitos sin entenderlos. En cualquier caso, te lo voy a poner fácil: aquí tienes el código exacto que usamos para generar cada una de estas visualizaciones.
Antes de que sigas, un aviso:
🔒 Esta sección está detrás de un muro de pago. No porque me guste poner barreras, sino porque el conocimiento que realmente vale la pena no debería ser gratis. Si quieres acceder a estos scripts y empezar a generar tus propias visualizaciones como un pro, únete a la comunidad premium.
Continúa leyendo con una prueba gratuita de 7 días
Suscríbete a The Learning Curve para seguir leyendo este post y obtener 7 días de acceso gratis al archivo completo de posts.