

Practical GenAI Roadmap: Transformers y BERT Model
Cómo funcionan los modelos que cambiaron la historia del lenguaje automático (y por qué deberías entenderlos si trabajas con IA generativa)

Introducción
En el mundo de la IA generativa, nombres como ChatGPT, Gemini o Claude son ya parte del vocabulario diario. Pero bajo el capó, la verdadera revolución empezó hace unos años con un cambio de paradigma silencioso: los modelos Transformer y, en particular, BERT.
Este artículo es parte de nuestra serie Practical GenAI Roadmap, donde explicamos los fundamentos detrás de la IA generativa de forma clara y aplicada. Hoy toca entender qué es un Transformer, cómo funciona el modelo BERT y por qué estas dos piezas cambiaron el juego para siempre.
1. Antes de los Transformers
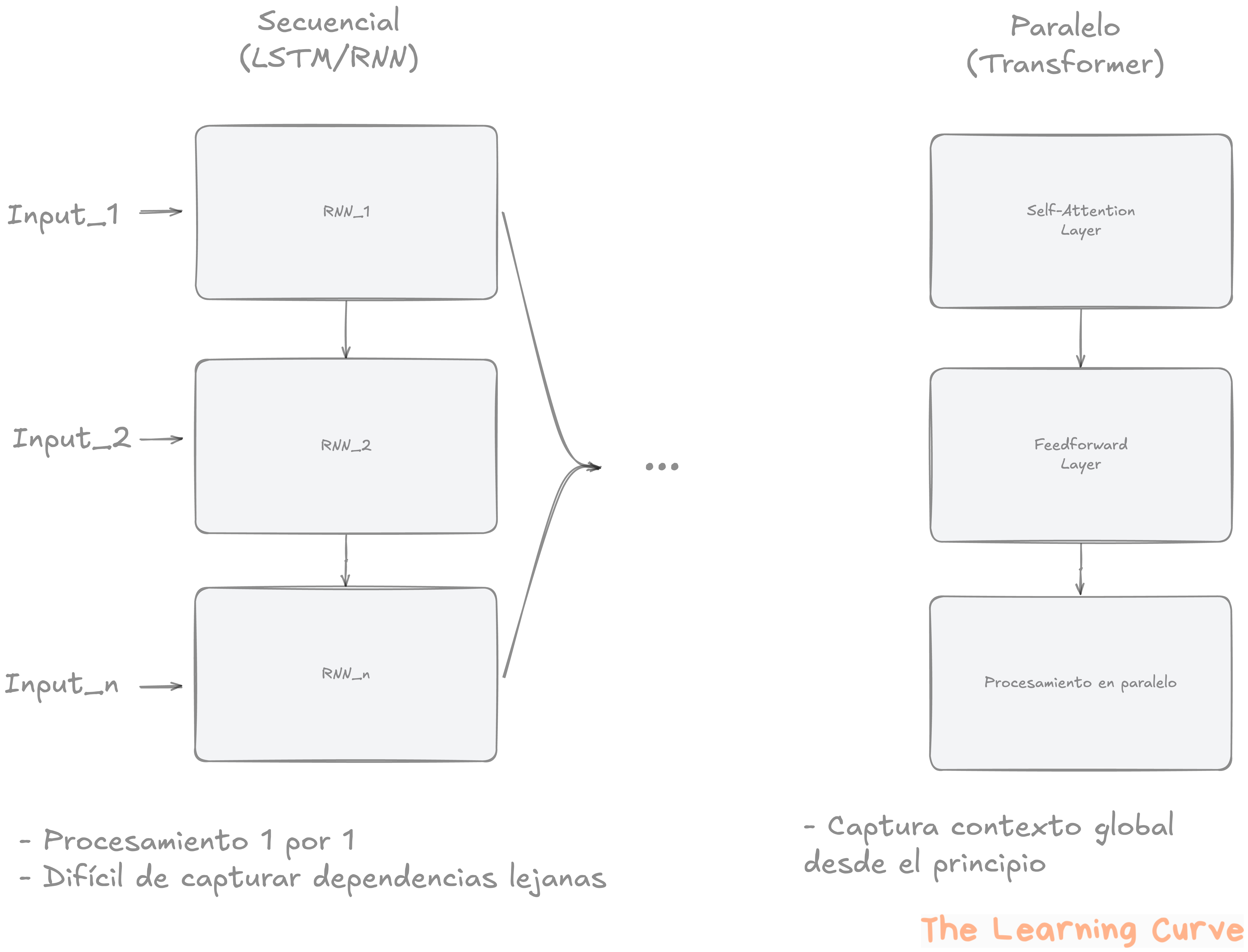
Antes de que los Transformers revolucionaran el procesamiento del lenguaje natural, los modelos más comunes eran las Redes Neuronales Recurrentes (RNN) y sus variantes más sofisticadas como LSTM (Long Short-Term Memory) y GRU.
Estos modelos procesaban el texto de manera secuencial, palabra por palabra. Esto significa que para interpretar una frase como:
“El hombre que conocí en París, donde viví varios años, tenía una historia fascinante.”
… el modelo debía ir palabra por palabra, actualizando su "memoria interna" en cada paso. En teoría, podía recordar el contexto anterior, pero en la práctica, a medida que la secuencia se alargaba, la información importante se desvanecía. Este fenómeno se conoce como el problema del desvanecimiento del gradiente, y hacía muy difícil capturar relaciones a largo plazo en los textos.
Además, el procesamiento secuencial impedía aprovechar el paralelismo de los GPUs. Había que esperar a procesar la palabra anterior antes de continuar, lo que ralentizaba el entrenamiento y la inferencia.
Todo esto cambió en 2017, cuando un grupo de investigadores de Google publicó el paper “Attention is All You Need”. Propusieron una arquitectura radicalmente distinta: el Transformer, que eliminaba la dependencia secuencial y permitía procesar todas las palabras al mismo tiempo.
El núcleo de su propuesta era el mecanismo de atención, una forma de identificar qué palabras eran más relevantes dentro de una frase, sin necesidad de seguir un orden fijo. Esta idea no solo resolvía las limitaciones técnicas, sino que también permitía una mejor comprensión del lenguaje.
2. La arquitectura Transformer: encoder y decoder
La arquitectura Transformer se compone de dos bloques principales: el encoder y el decoder. Aunque ambos siguen una estructura modular y repetitiva, cada uno tiene un rol distinto en el procesamiento del lenguaje.
Encoder
El encoder es el encargado de leer el texto de entrada y convertirlo en una representación numérica rica en contexto. Este proceso permite que cada palabra no solo conserve su significado individual, sino también su relación con el resto del texto.
Cada encoder está formado por varias capas idénticas (el paper original propone seis, aunque modelos actuales utilizan decenas o incluso cientos). Cada capa contiene dos subcomponentes clave:
Capa de Self-Attention: evalúa el peso o relevancia que tiene cada palabra respecto a las demás dentro de la misma secuencia.
Capa Feedforward: una red MLP que transforma la información para su uso en la siguiente capa.
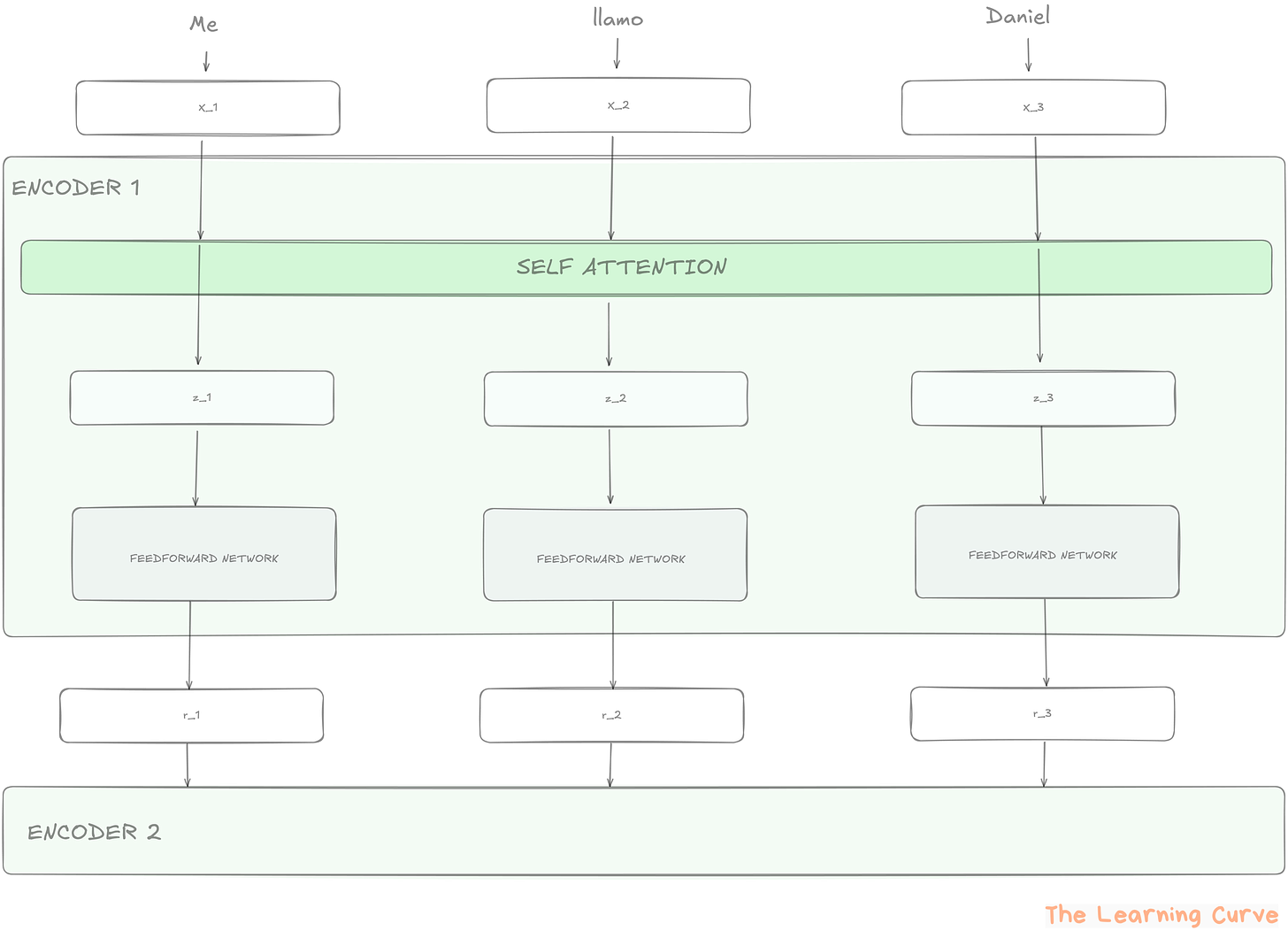
Estas capas se combinan con elementos adicionales que resultan esenciales para un entrenamiento efectivo:
Conexiones residuales, que permiten saltarse capas para facilitar el flujo del gradiente.
Normalización por capas (Layer Normalization), que estabiliza el entrenamiento.
Dropout, que ayuda a evitar el sobreajuste.
Decoder
El decoder se utiliza principalmente en tareas generativas. Su objetivo es producir una salida (por ejemplo, una frase traducida) basándose en las representaciones producidas por el encoder.
Cada capa del decoder incluye tres componentes:
Una self-attention como la del encoder, pero con una máscara que impide que el modelo “vea” futuras posiciones, para mantener la generación paso a paso.
Una attention cruzada, que permite al decoder acceder a la salida del encoder.
Una capa feedforward, igual que en el encoder.
Procesamiento en paralelo
Una de las principales innovaciones del Transformer es que permite procesar todos los tokens simultáneamente, en lugar de hacerlo uno a uno como en los modelos RNN. Esto se logra gracias al mecanismo de atención, que no requiere conocer la salida previa para procesar la siguiente palabra.
Este paralelismo no solo mejora la eficiencia en el entrenamiento, sino que permite escalar los modelos a tamaños impensables en arquitecturas anteriores.
📤 ¿Te resultó útil? Compártelo en Twitter o LinkedIn y ayúdame a llegar a más mentes curiosas.
3. Cómo funciona la self-attention
El mecanismo de self-attention (o atención propia) es el núcleo del Transformer. Permite que cada palabra de una frase considere a todas las demás para construir una representación contextualizada, es decir, entender no solo su significado aislado, sino también su papel dentro del conjunto.
Paso a paso: del token a la atención
Para cada palabra (token) en la secuencia, el modelo genera tres vectores:
Query (Q): representa la palabra que “hace la pregunta”.
Key (K): representa las palabras que pueden “responder” a esa pregunta.
Value (V): representa la información que se quiere obtener si la atención es alta.
La atención se calcula comparando el vector Query de una palabra con los vectores Key de todas las demás. Esta comparación se hace mediante un producto escalar, que mide cuán alineados están los vectores.
A continuación:
Se divide el producto escalar por la raíz cuadrada de la dimensión de los vectores (para estabilizar los gradientes).
Se aplica una función softmax para convertir esas puntuaciones en probabilidades.
Finalmente, se multiplica cada vector Value (V) por su peso de atención correspondiente, y se suman todos para obtener la representación final de la palabra.
Ejemplo simple
Imaginemos la frase:
“El gato duerme en el sofá.”
Cuando el modelo analiza la palabra “duerme”, puede prestar especial atención a “gato” (el sujeto que realiza la acción), mientras que otorga menos peso a palabras como “el” o “en”. La atención permite que la representación de “duerme” incorpore información sobre “gato”, incluso si no están una al lado de la otra.
Ventaja frente a modelos anteriores
En arquitecturas como RNN o LSTM, esta relación debía aprenderse a través del estado oculto, paso a paso. En cambio, self-attention permite establecer directamente conexiones entre cualquier par de palabras, sin importar su distancia. Esta capacidad para modelar dependencias largas es uno de los factores que explican el éxito del Transformer.
4. Multi-head attention: varias perspectivas en paralelo
El mecanismo de self-attention por sí solo ya aporta una gran mejora respecto a las arquitecturas anteriores. Pero los autores del Transformer fueron un paso más allá e introdujeron una mejora clave: la atención multi-cabeza (multi-head attention).
¿Qué significa tener varias “cabezas” de atención?
En lugar de calcular un único conjunto de vectores Q, K y V para cada palabra, el modelo genera varias versiones distintas de esos vectores, cada una con pesos propios. A cada conjunto se le llama una “cabeza de atención”.
Cada cabeza aprende a enfocarse en distintos aspectos del texto. Por ejemplo:
Una cabeza puede especializarse en relaciones gramaticales (sujeto-verbo).
Otra en estructuras semánticas (sinónimos, temas).
Otra en dependencias a larga distancia (como una referencia al inicio del párrafo).
Este enfoque permite que el modelo vea el mismo texto desde distintas perspectivas de forma simultánea.
¿Cómo funciona técnicamente?
Cada cabeza aplica su propia versión del mecanismo de self-attention, con vectores Q, K y V distintos.
El resultado de cada cabeza es una representación diferente del mismo token.
Al final, se concatena el resultado de todas las cabezas y se pasa por una capa lineal para integrarlo todo en una única salida coherente.
Ventajas del enfoque multi-head
Mejora la capacidad del modelo para capturar diferentes tipos de relaciones en el texto.
Aumenta la expresividad sin incrementar la complejidad computacional de forma drástica.
Hace más robusta la representación de cada palabra al no depender de una única fuente de atención.
Este mecanismo es fundamental para el rendimiento de los modelos actuales. Sin él, los Transformers no tendrían la flexibilidad necesaria para entender contextos complejos, dobles significados o ambigüedades.
5. ¿Qué es BERT y por qué fue un antes y un después?
En 2018, Google presentó BERT (Bidirectional Encoder Representations from Transformers), un modelo que marcó un punto de inflexión en el procesamiento del lenguaje natural. Aunque se basa en la arquitectura Transformer, BERT introdujo una serie de ideas clave que redefinieron la forma en que se entrenan y utilizan los modelos de lenguaje.
Solo el encoder, pero mejorado
A diferencia de modelos como GPT, que utilizan únicamente la parte decoder del Transformer, BERT emplea solo la parte encoder. Esto significa que BERT no genera texto, sino que produce representaciones profundas del lenguajeque pueden usarse como base para muchas tareas: clasificación, preguntas y respuestas, extracción de entidades, etc.
Pero lo verdaderamente revolucionario no fue solo eso.
Bidireccionalidad: la gran diferencia
Los modelos anteriores solían ser unidireccionales, es decir, leían las frases de izquierda a derecha (como GPT) o, en algunos casos, de derecha a izquierda.
BERT cambió esto por completo: fue el primer modelo ampliamente adoptado en utilizar bidireccionalidad profundadesde el principio. Esto quiere decir que, al analizar una palabra, BERT tiene en cuenta tanto el contexto que la precede como el que la sigue.
Por ejemplo, en la frase:
“El banco estaba cerrado cuando llegamos.”
Para entender la palabra “banco”, BERT analiza simultáneamente si hay pistas antes (“El”) y después (“cerrado”) para determinar si se refiere a una institución financiera o a un asiento. Este entendimiento contextual más completo mejora drásticamente la precisión del modelo en tareas como clasificación o comprensión de texto.
¿Por qué fue tan disruptivo?
Antes de BERT, muchos modelos requerían que se entrenara un sistema desde cero para cada tarea concreta. BERT, en cambio, se entrena primero con una tarea general (preentrenamiento) y luego se adapta rápidamente a tareas específicas con unos pocos datos (fine-tuning).
Esta combinación de:
Arquitectura basada en encoder
Bidireccionalidad
Uso universal del preentrenamiento
… lo convirtió en un modelo base reutilizable para decenas de tareas distintas, reduciendo el tiempo y el coste de desarrollo en aplicaciones reales.
Desde su publicación, BERT no solo ha influido en nuevas variantes como RoBERTa, ALBERT o DistilBERT, sino que también se ha convertido en el modelo por defecto para muchas tareas de procesamiento de lenguaje natural en la industria y la investigación.
8. ¿Y qué se puede hacer con BERT?
BERT puede aplicarse (fine-tuned) a muchas tareas:
Clasificación de texto
Análisis de sentimiento
Preguntas y respuestas
Detección de entidades
Similitud semántica
Traducción (con adaptaciones)
De hecho, Google Search lo utiliza desde 2019 para entender mejor tus búsquedas.
🗣️ ¿Te ha quedado alguna duda? ¿Qué tema te gustaría que tratase en el próximo artículo?
Deja tu comentario o responde a este email si estás suscrito.
🎙️ ¿Te interesa cómo aplico todo esto en proyectos reales?
En el podcast “Cuaderno de Bitácora” te cuento cada semana cómo voy creando un producto digital con IA, sin humo y con todos los tropiezos incluidos.