

Practical GenAI Roadmap: Introducción a la generación de imágenes
Una guía práctica para entender cómo funcionan los modelos que transforman ruido en arte digital. Desde los fundamentos físicos hasta las herramientas que ya puedes usar.

Si alguna vez has usado Midjourney, DALL·E o Stable Diffusion, seguro que te has preguntado:
¿cómo cojo** sabe la IA que quiero una cabra montesa con gafas de sol en estilo cyberpunk?
La respuesta corta: gracias a los modelos de difusión.
La larga... es justo lo que vamos a explicar hoy.
En los últimos meses, la generación de imágenes se ha convertido en uno de los campos más potentes (y más espectaculares) de la inteligencia artificial.
Y sin embargo, la mayoría de explicaciones siguen siendo crípticas, técnicas o directamente mágicas.
Yo también me perdía con ecuaciones y nombres raros hasta que entendí una cosa:
Los modelos de generación de imágenes no imaginan. Aprenden a revertir el caos.
En esta guía te voy a contar paso a paso cómo funciona esto.
Desde los primeros enfoques hasta los últimos avances en modelos de difusión, que ya están detrás de productos de Google, Adobe y OpenAI.
Vamos a empezar por el principio.
Pero si estás con prisa, aquí va una mini-spoiler de lo que vas a entender al acabar este post:
Qué son los modelos generativos y cómo evolucionaron
Por qué los modelos de difusión lo están petando (y cómo funcionan por dentro)
Qué significa eso de “empezar desde ruido”
Cómo se combinan con LLMs para crear imágenes que parecen salidas de una cámara de fotos
Y como siempre, todo explicado en cristiano, sin humo ni promesas mágicas.
Modelos generativos clásicos
Los modelos generativos no son nuevos (pero han mejorado muchísimo)
Aunque parezca que todo esto ha surgido de la nada en 2022 o 2023, la verdad es que la generación de imágenes con IA tiene historia.
Antes de Stable Diffusion o Midjourney, ya existían modelos capaces de crear imágenes que nunca habían existido.
Los más importantes han sido:
Variational Autoencoders (VAE)
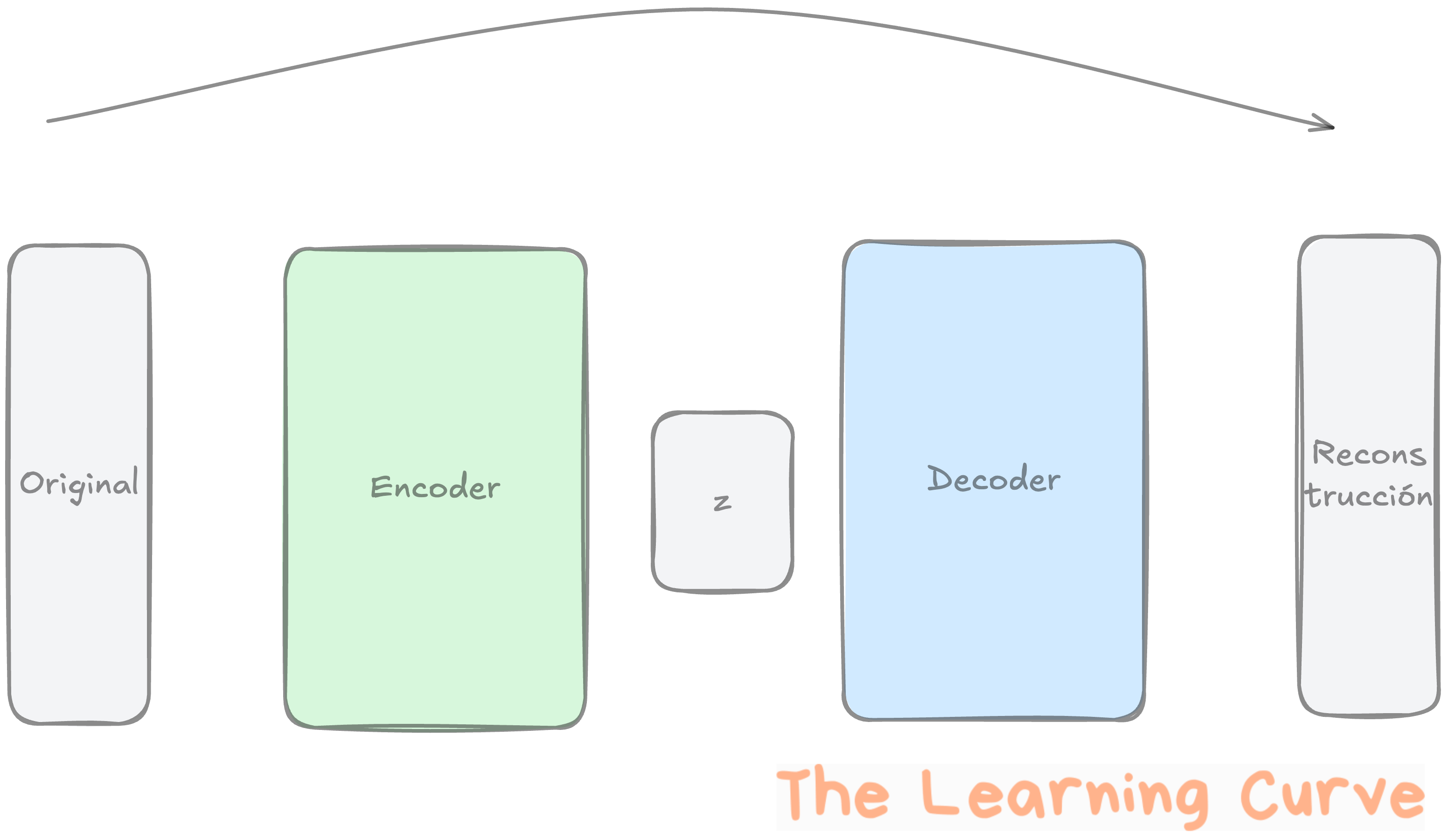
Los VAEs fueron una de las primeras arquitecturas que nos permitieron generar imágenes nuevas.
La idea básica es sencilla:
Toman una imagen y la comprimen en una representación más pequeña, llamada espacio latente.
Luego intentan reconstruirla a partir de esa representación.
En el proceso, aprenden la “forma” de los datos: qué es típico y qué no.
Esto los hace útiles para generar imágenes nuevas parecidas a las del conjunto de entrenamiento.
Por ejemplo, si entrenas un VAE con muchas fotos de gatos, puede generar gatos nuevos (aunque algo borrosos).
Ventajas:
Fáciles de entrenar.
Interpretables (puedes entender qué hay en el espacio latente).
Límites:
Las imágenes generadas suelen ser difusas o borrosas.
No tienen tanta capacidad de generar detalles finos o realismo fotográfico.
Generative Adversarial Networks (GANs)
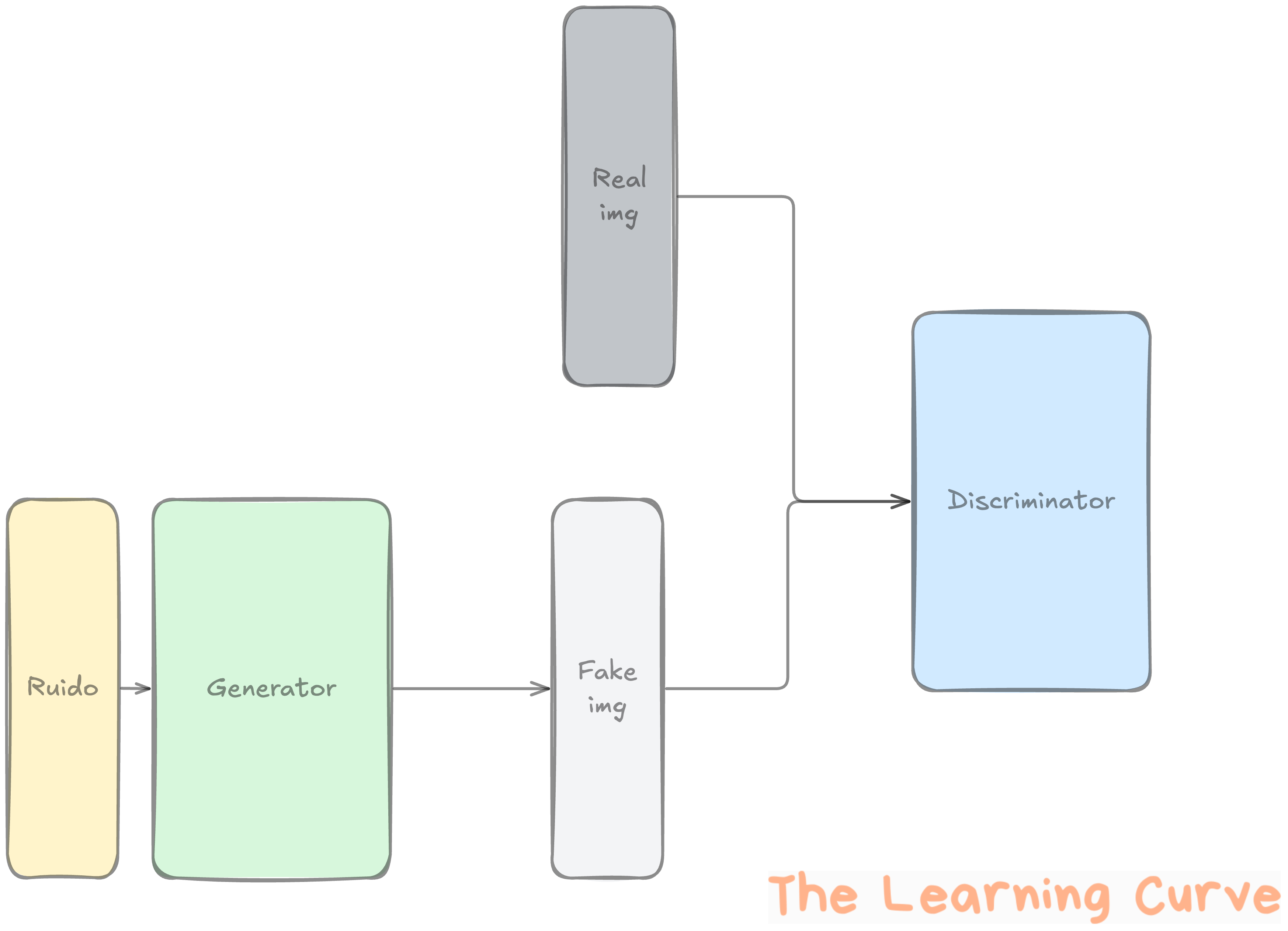
Los GANs fueron el siguiente gran salto.
Aquí entramos en terreno más agresivo: en vez de un solo modelo, tenemos dos que compiten entre sí:
Un generador que crea imágenes falsas.
Un discriminador que intenta distinguir si la imagen es real o falsa.
Ambos modelos mejoran al enfrentarse continuamente.
Es como un falsificador y un policía que se entrenan mutuamente.
Ventajas:
Imágenes mucho más realistas que con VAEs.
Gran éxito en tareas como deepfakes, generación de rostros, arte, etc.
Límites:
Muy difíciles de entrenar (pueden ser inestables).
Problemas como mode collapse (el generador se obsesiona con un único tipo de imagen).
Modelos Autoregresivos
Este enfoque trata una imagen como una secuencia de píxeles.
Sí, como si fuera texto.
De hecho, algunos modelos como PixelRNN o PixelCNN procesan la imagen píxel a píxel, de izquierda a derecha, línea a línea.
Más recientemente, los modelos como Imagen GPT o VQ-VAE-2 han usado técnicas similares a los LLMs.
Ventajas:
Mucho control sobre el orden y composición.
Han permitido avances en imagen + texto.
Límites:
Lentos: generar imagen por píxel o por patch lleva tiempo.
Menos eficientes para capturar estructuras globales de la imagen.
Entonces… ¿qué problema resuelven los modelos de difusión?
Hasta aquí teníamos:
Modelos fáciles de entrenar pero poco realistas (VAEs).
Modelos realistas pero inestables (GANs).
Modelos precisos pero lentos (autoregresivos).
Los modelos de difusión llegaron como una mezcla de lo mejor de cada casa:
Estables y fáciles de entrenar.
Capaces de generar imágenes de altísima calidad.
Y con posibilidad de controlar y guiar la generación con texto, imágenes u otras señales.
Y ahora que tenemos el contexto… vamos al plato fuerte.
Qué son los modelos de difusión (y por qué es diferente)
Los modelos de difusión llegaron sin hacer mucho ruido.
Literalmente.
Porque lo que hacen es añadir ruido a las imágenes hasta destruirlas... para luego aprender a reconstruirlas desde cero.
Puede sonar contraintuitivo, pero esa es la esencia:
Destruir el orden de una imagen paso a paso, y luego entrenar a una IA para que aprenda a revertir ese proceso.
Y lo más fascinante: una vez que el modelo ha aprendido a reconstruir imágenes a partir de ruido,
podemos darle como entrada solo ruido y generar una imagen completamente nueva.
Inspiración en la física: termodinámica en acción
Este enfoque no viene de la biología, ni del arte, ni del lenguaje.
Viene de la física, concretamente de la termodinámica estocástica.
En física, se puede modelar cómo una partícula pasa de un estado ordenado a uno caótico por efecto del ruido térmico. (No me pidas que te de más explicaciones que no soy físico, si tienes alguna duda al respecto, puedes ir a preguntar a
, que antes de dedicarse a la IA, era científico o algo así)
En los modelos de difusión, esta idea se lleva al mundo de los datos visuales:
Fase 1: tomar una imagen y corromperla poco a poco añadiendo ruido gaussiano.
Fase 2: aprender a hacer el proceso inverso, quitando ese ruido paso a paso.
Este proceso permite modelar de forma muy precisa la distribución estadística de los datos (las imágenes).
Y eso es justo lo que permite crear contenido nuevo que parece haber sido sacado del conjunto original, aunque nunca haya existido.
Por qué son diferentes
Hay varias razones por las que los modelos de difusión han despegado tan fuerte:
Generan imágenes con calidad fotográfica. Algunos resultados son tan buenos que cuesta distinguir si son reales o no.
Son estables al entrenar. A diferencia de GANs, que son impredecibles, los modelos de difusión aprenden de forma robusta.
Se pueden guiar con texto, imágenes o máscaras. Lo que los hace ideales para tareas como text-to-image, edición, o rellenado.
Permiten múltiples estilos y niveles de control. Podemos condicionar la generación, editar contenido, o incluso fusionar estilos visuales.
Además, en los últimos años se han mejorado muchísimo en términos de velocidad y eficiencia.
Modelos como Latent Diffusion Models (LDM) reducen el coste computacional sin perder calidad, y modelos como Stable Diffusion o Imagen los han llevado al mundo real.
El proceso de difusión paso a paso
Los modelos de difusión funcionan gracias a un ciclo de dos fases: una de destrucción y otra de reconstrucción.
Dicho en términos técnicos:
Forward process (proceso hacia adelante): añadir ruido de forma progresiva a una imagen hasta que no quede nada reconocible.
Reverse process (proceso inverso): entrenar una IA para aprender a quitar ese ruido paso a paso, hasta recuperar (o generar) una imagen coherente.
Vamos a descomponer cada uno para que se entienda bien.
1. Forward process: añadir ruido
Empezamos con una imagen normal. Pongamos, por ejemplo, un retrato.
En cada paso del proceso hacia adelante, le añadimos un poco de ruido gaussiano.
Cuanto más pasos hagamos, más se degrada la imagen.
Después de unos cientos (o miles) de pasos, no queda nada. Solo ruido.
Formalmente, a esto se le llama una cadena de Markov:
cada imagen ruidosa solo depende del paso anterior, y la cantidad de ruido se controla con una variable llamada beta.
Este proceso es completamente conocido. No necesita aprenderse.
Es simplemente una fórmula que se repite en bucle:
x₀ → x₁ → x₂ → ... → xₜ
donde x₀ es la imagen original y xₜ es solo ruido.
2. Reverse process: quitar ruido (a lo bestia)
Y aquí es donde entra la IA.
La tarea del modelo es aprender a revertir ese proceso. Es decir, que si le das una imagen ruidosa, te diga qué parte es ruido y cuál sería la versión más limpia.
Así, paso a paso, va recuperando estructura.
¿Cómo se entrena eso?
Muy simple:
Tienes la imagen original
x₀.La corrompes a un paso aleatorio
xₜañadiendo ruido.Le pides al modelo que prediga solo el ruido que añadiste.
Comparas su predicción con el ruido real y corriges el error.
Es un entrenamiento clásico de aprendizaje supervisado:
predicción vs. etiqueta. Solo que la etiqueta es… ruido.
3. El ciclo completo: de ruido puro a imagen nítida
Una vez entrenado el modelo, podemos darle como entrada una imagen de puro ruido aleatorio.
Y desde ahí, se aplica el modelo en sentido inverso, paso a paso:
z₀ → z₁ → z₂ → ... → z₀ (imagen final)
En cada paso, el modelo estima el ruido y lo va eliminando parcialmente, acercándose cada vez más a una imagen coherente.
¿Resultado? Una imagen completamente nueva, pero con características similares a las que había en el set de entrenamiento.

Este proceso tiene algo muy especial:
el modelo no está memorizando imágenes. Está aprendiendo a modelar la distribución completa de los datos visuales.
Y eso lo convierte en una herramienta muy flexible.
No solo puede generar imágenes nuevas, también puede hacer cosas como:
Mejorar imágenes pixeladas (super resolution).
Editar partes específicas de una imagen.
Convertir texto en imagen con un estilo particular.
Cómo se generan imágenes desde cero
Hasta ahora hemos visto cómo el modelo aprende a quitar ruido.
Pero… ¿cómo se convierte eso en una imagen completamente nueva?
Muy simple:
Se parte de una imagen que es puro ruido, y se le va quitando ese ruido poco a poco.
Así de fácil. Y así de potente.
Paso a paso: del caos al orden
Generamos una imagen aleatoria
Literalmente: un montón de píxeles ruidosos, sin ninguna estructura.Aplicamos el modelo entrenado para predecir el ruido
El modelo ha aprendido, durante el entrenamiento, a detectar y eliminar ese ruido paso a paso.En cada iteración, el ruido se reduce ligeramente
Se hace de forma progresiva: no pasamos de ruido a imagen en un solo salto, sino en 50, 100, 250 pasos (dependiendo del modelo).Al final del proceso, lo que queda ya no es ruido: es una imagen coherente
Una cara, un perro, una escena urbana, un paisaje ficticio…
Lo que sea que haya aprendido el modelo.
¿Y qué se genera?
Eso depende de cómo hayas entrenado el modelo:
Si solo le diste imágenes de caras, generará caras nuevas.
Si usaste paisajes, generará paisajes.
Si es un modelo condicionado, puedes decirle qué tipo de imagen quieres y el resultado será aún más controlado (esto lo cubrimos en el siguiente apartado).
Esta idea de “empezar desde ruido” es lo que hace que los modelos de difusión sean tan diferentes.
No se basan en copiar ni recombinar imágenes, sino en aprender la estructura de los datos y recrearla desde cero.
Un ejemplo real
Modelos como Stable Diffusion o Imagen (de Google) funcionan exactamente así.
Cuando le escribes algo como:
"A futuristic city skyline at sunset, painted in watercolor style"
Lo que pasa por debajo es:
El texto se convierte en una representación latente (embedding).
Se genera una imagen ruidosa.
El modelo va eliminando el ruido, guiado por ese texto, hasta obtener una imagen coherente con la descripción.
Así es como logramos resultados que parecen mágicos… pero tienen una lógica muy clara detrás.
Tipos de generación con modelos de difusión
Hasta ahora hemos hablado del proceso de generación como si todos los modelos hicieran lo mismo: generar imágenes desde cero.
Pero en realidad, existen varias formas de generar imágenes, según el tipo de entrada o “condición” que le demos al modelo.
Los dos grandes grupos son:
Generación no condicionada: el modelo no recibe instrucciones, solo genera imágenes nuevas en función de lo que aprendió.
Generación condicionada: el modelo recibe una guía, como un texto, una imagen parcial o una máscara, y genera en función de eso.
Vamos a ver cada una con más detalle.
¿Te interesaría aprender a crear agentes de IA desde cero?

En 2025 he facturado más de 20.000 € desarrollando agentes de inteligencia artificial personalizados.
1. Generación no condicionada
Es el caso más puro. El modelo genera imágenes sin ningún tipo de input adicional. Solo ruido como punto de partida.
Por ejemplo:
Un modelo entrenado con millones de caras humanas puede generar rostros completamente nuevos.
Un modelo entrenado con imágenes de coches puede generar diseños de vehículos nunca vistos.
Este tipo de generación sirve, sobre todo, para:
Evaluar la calidad general del modelo.
Ampliar datasets sintéticos.
Crear ejemplos en dominios muy específicos (biomedicina, moda, etc.).
Pero lo interesante empieza cuando añadimos control…
2. Generación condicionada
Aquí es donde los modelos de difusión se vuelven realmente útiles para tareas del mundo real.
Puedes decirle a la IA qué quieres generar, cómo y dónde.
Existen varios tipos de condicionamiento:
a) Text-to-image
El más conocido. Le das un texto y el modelo genera una imagen que se ajusta a esa descripción.
Por ejemplo:
“A steampunk astronaut riding a mechanical horse through the desert”
El texto se convierte en una representación numérica (embedding), y ese embedding guía el proceso de generación.
Es como si el modelo empezara con ruido, pero con una brújula que le dice hacia dónde moverse.
Modelos conocidos que usan este enfoque:
Imagen (Google)
DALL·E 2 / 3 (OpenAI)
Stable Diffusion (Stability AI)
b) Inpainting o edición de imágenes
![r/MachineLearning - [R] "Deep Image Prior": deep super-resolution, inpainting, denoising without learning on a dataset and pretrained networks](https://substackcdn.com/image/fetch/$s_!XRMv!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe5ea81d5-c116-4688-89be-b4d049860198_640x378.jpeg "r/MachineLearning - [R] \"Deep Image Prior\": deep super-resolution, inpainting, denoising without learning on a dataset and pretrained networks")
Aquí no se parte de cero, sino que el modelo recibe una imagen con una parte faltante o modificable, y se le pide que la complete de forma coherente.
Es ideal para:
Rellenar huecos.
Corregir errores.
Cambiar partes específicas de una imagen (ponle un sombrero, cambia el fondo, etc.).
c) Image-to-image o edición guiada por texto
Una variante más avanzada: se parte de una imagen, pero también se le da al modelo un texto con instrucciones.
Por ejemplo:
Imagen original: una taza de café.
Prompt: “Make it look like it’s snowing”.
El modelo mantiene la estructura básica, pero modifica la imagen para ajustarse al texto.
Esto es útil en diseño, fotografía, publicidad y creación de contenido audiovisual.
d) Super resolution
Una aplicación muy práctica: mejorar la resolución de imágenes.
Especialmente útil para restaurar fotos antiguas, documentos escaneados o imágenes comprimidas.
El modelo parte de una imagen en baja resolución y la “imagina” con más detalle, guiándose por lo que aprendió durante el entrenamiento.
No es un simple resize como hace Photoshop: el modelo genera píxeles nuevos que tienen sentido visual.
Ventajas (y retos) de los modelos de difusión
Los modelos de difusión han pasado en pocos años de ser una curiosidad académica a convertirse en el pilar central de la generación de imágenes con IA.
Pero como cualquier tecnología, tienen luces… y sombras.
Ventajas claras
1. Calidad de imagen excepcional
Los modelos de difusión generan imágenes con una calidad que rivaliza (y en muchos casos supera) a los mejores GANs.
Detalles nítidos, coherencia visual, iluminación realista, texturas complejas…
Incluso en tareas como text-to-image, donde el reto es doble (entender el texto y generar la imagen), ofrecen resultados fotorealistas.
2. Estabilidad en el entrenamiento
Una de las grandes pesadillas de los GANs era entrenarlos: el generador y el discriminador entraban en dinámicas caóticas que podían acabar en resultados mediocres o en “mode collapse”.
Los modelos de difusión no tienen ese problema.
Se entrenan como cualquier modelo supervisado, prediciendo ruido, lo que los hace mucho más robustos y fáciles de escalar.
3. Flexibilidad de uso
Como ya vimos, puedes usarlos para:
Generar imágenes desde cero.
Rellenar zonas vacías.
Guiarlos con texto, imágenes o máscaras.
Hacer superresolución o transferir estilos.
Y eso los convierte en herramientas ideales para tareas creativas, médicas, industriales, educativas y más.
4. Interpretabilidad y control
Aunque parezca contradictorio, es más fácil entender qué está haciendo un modelo de difusión que un GAN.
Cada paso del proceso de denoising es interpretable y se puede inspeccionar.
Además, permite insertar condiciones en puntos específicos del pipeline, lo que da mucho control sobre el resultado final.
Retos y limitaciones
1. Coste computacional
Uno de los mayores desafíos es el tiempo de generación.
Un GAN genera una imagen en una sola pasada.
Un modelo de difusión puede requerir entre 50 y 100 pasos de inferencia.
Aunque ya existen versiones optimizadas (como DDIM o Latent Diffusion Models), sigue siendo una barrera en entornos con recursos limitados o para aplicaciones en tiempo real.
2. Riesgo de uso indebido
Como con cualquier herramienta poderosa, existe el riesgo de que se use para:
Generar deepfakes.
Crear contenido engañoso.
Replicar el estilo de artistas sin consentimiento.
Por eso muchas empresas (como OpenAI o Google) han limitado el acceso a algunos modelos o incorporado mecanismos de trazabilidad.
3. Dependencia del dataset de entrenamiento
Aunque los modelos pueden generar contenido "nuevo", están fuertemente condicionados por los datos con los que se entrenaron.
Si el dataset tiene sesgos, errores o limitaciones, esos mismos problemas pueden aparecer en las imágenes generadas.
Y además, no es trivial garantizar que no se filtren contenidos problemáticos o información sensible.
Casos reales: de rostros sintéticos a arte generado con texto
Ahora que ya sabes cómo funcionan los modelos de difusión, toca ver qué se ha construido con ellos.
Porque sí: esta tecnología ya está en el corazón de productos reales, que se usan millones de veces al día.
Desde diseñadores freelance hasta grandes empresas tecnológicas.
Vamos a recorrer algunos de los casos más emblemáticos.
1. StyleGAN (GANs, pero relevante como referencia)
Antes de que los modelos de difusión se llevaran el protagonismo, StyleGAN de NVIDIA dominaba el juego.
Fue el responsable de webs como ThisPersonDoesNotExist.com, donde se generan rostros humanos completamente ficticios con un realismo asombroso.
Aunque StyleGAN se basa en GANs, sigue siendo un referente visual y técnico que marcó un antes y un después en la generación de imágenes sintéticas.
2. Imagen (Google)
Uno de los modelos más avanzados en cuanto a calidad de imagen y fidelidad al prompt.
Entrenado sobre un potente modelo de lenguaje y una arquitectura de difusión en múltiples fases, Imagen demostró que se podía generar contenido hiperrealista solo con texto.
Google ha presentado demos como:
“Un oso panda haciendo malabares con frutas en una calle de Tokio, con estilo acuarela”
Y el resultado parece sacado de una ilustración profesional.
Lo interesante de Imagen no es solo la calidad, sino su pipeline:
usa un modelo de lenguaje para interpretar el prompt y múltiples modelos de difusión para generar la imagen final.
3. DALL·E 2 y 3 (OpenAI)
Probablemente los más populares a nivel de usuario.
DALL·E 2 introdujo una interfaz sencilla y resultados creativos, aunque algo inconsistentes.
DALL·E 3 dio un salto enorme en coherencia semántica y control sobre el prompt gracias a su integración con GPT-4.
Hoy puedes escribir algo como:
“Un cartel vintage anunciando café en París, con estilo de los años 50”
Y DALL·E 3 no solo genera una imagen coherente, sino que entiende los matices del estilo, el contexto cultural y la composición visual.
Además, soporta inpainting y edición de imágenes directamente desde el prompt.
4. Stable Diffusion (Stability AI)
El primer gran modelo de difusión de código abierto y uso libre.
Su impacto fue enorme por varias razones:
Cualquiera podía instalarlo y generar imágenes localmente.
Se popularizaron herramientas como Automatic1111, InvokeAI o ComfyUI para usarlo sin programar.
La comunidad creó miles de modelos derivados y afinados para estilos concretos (anime, fotografía, 3D, etc.).

Stable Diffusion también introdujo el concepto de Latent Diffusion, donde el proceso se realiza sobre una versión comprimida de la imagen.
Esto reduce los costes y acelera la inferencia.
5. Aplicaciones reales en empresas
No es solo arte o curiosidades de Internet.
Hoy, los modelos de difusión se usan en:
E-commerce: para generar fotos de productos con fondos personalizados.
Moda: para crear prototipos visuales de prendas antes de fabricarlas.
Arquitectura y diseño: para renderizados rápidos de interiores o exteriores.
Medicina: para simular tejidos, tumores o escenarios clínicos en datasets sintéticos.
Publicidad y redes sociales: para campañas visuales únicas y personalizadas.
Qué viene después: difusión + lenguaje = imaginación contextual
Generar imágenes con IA ya era impresionante.
Pero cuando combinas un modelo de imagen con un modelo de lenguaje...
lo que obtienes es una interfaz creativa conversacional.
Una máquina capaz de transformar ideas en imágenes. Literalmente.
De “generar imágenes” a “entender conceptos”
Un modelo de difusión puede generar imágenes…
Pero no entiende el mundo.
No sabe que “una bicicleta sobre una nube” es surrealista.
Ni que “una boda medieval en la luna” es una combinación absurda pero coherente.
Ahí es donde entran los LLMs (Large Language Models).
Estos modelos han sido entrenados con lenguaje natural, historias, conceptos culturales, metáforas…
Y eso les permite entender el contexto, la intención y los matices de un prompt.
Cómo se combinan
El enfoque moderno combina ambos mundos:
El modelo de lenguaje interpreta el texto y genera una representación semántica rica (lo que tú quieres decir).
Esa representación se convierte en una condición para el modelo de difusión, que genera una imagen coherente con ese significado.
Este acoplamiento permite resultados muchísimo más precisos y controlables.
Modelos que ya funcionan así
DALL·E 3 + GPT-4
Cuando escribes un prompt largo y complejo, GPT-4 lo reescribe internamente en un formato optimizado para el modelo de imagen.
Esto mejora la fidelidad entre lo que pides y lo que obtienes.
Además, puedes editar la imagen con instrucciones naturales:
"Haz que el perro tenga un gorro de cumpleaños".
Imagen (Google)
Usa un modelo de lenguaje entrenado por separado (T5) para entender mejor el contexto y descomponer la escena en elementos visuales.
Luego los pasa a un modelo de difusión en varias etapas para construir la imagen final.
Sora (OpenAI, 2024)
Aunque centrado en vídeo, sigue el mismo principio:
interpretar texto con un LLM, y usar modelos generativos para convertirlo en una secuencia visual.
¿Y lo multimodal?
La próxima frontera es la unificación de modalidades:
texto, imagen, audio, vídeo, código… todo en un mismo modelo.
Esto ya se está viendo con:
Gemini (Google)
GPT-4o (OpenAI)
Gato y otros modelos generalistas de DeepMind
La idea es que no tengas que usar un modelo para cada cosa, sino uno solo que pueda:
Leer un documento.
Entender una imagen.
Generar una respuesta.
Editar una foto.
Y generar un vídeo en el mismo contexto.
Una especie de asistente universal que trabaja sobre cualquier tipo de entrada o salida.
Recursos para aprender más
Si has llegado hasta aquí, ya sabes más sobre modelos de difusión que el 90% de Internet.
Pero si te ha picado la curiosidad y quieres seguir aprendiendo (o incluso crear tus propios generadores), aquí tienes una selección de recursos para explorar.
Lecturas técnicas (pero digeribles)
Paper original: “Denoising Diffusion Probabilistic Models”
Ho et al., 2020. El paper que reactivó la explosión de la difusión moderna.
https://arxiv.org/abs/2006.11239“High-Resolution Image Synthesis with Latent Diffusion Models”
El paper detrás de Stable Diffusion, explica cómo reducir costes generando en el espacio latente.
https://arxiv.org/abs/2112.10752
Cursos y notebooks
MIT 6.S183 A Practical Introduction to Diffusion Models, Lecture 1
Curso práctico de modelos de difusión. Curso completo aquíHugging Face Diffusers Course
Curso gratuito con código, vídeos y ejemplos prácticos usandodiffusers, una de las librerías estándar para generación con difusión.
https://huggingface.co/learn/diffusers-course
Repositorios útiles
Stable Diffusion (CompVis)
El repo oficial donde empezó todo.
https://github.com/CompVis/stable-diffusionDiffusers (Hugging Face)
Librería modular con acceso a múltiples modelos de difusión preentrenados.
https://github.com/huggingface/diffusersInvokeAI / ComfyUI / Automatic1111
Interfaces visuales para trabajar con modelos de difusión sin escribir código. Muy recomendables para experimentar.
Para experimentar sin programar
PlaygroundAI
Web para generar imágenes fácilmente con modelos como Stable Diffusion o DALL·E.Leonardo.Ai
Permite generar imágenes y entrenar tus propios modelos personalizados para proyectos visuales.Runway ML
Ideal para diseñadores, permite generación de imágenes y vídeo desde texto. Usado en producción por artistas visuales.
¿Y si solo tengo una hora libre esta semana?
Mira este vídeo:
What are Diffusion Models?
Si has llegado hasta aquí, ya no estás solo viendo imágenes generadas por IA.
Ahora sabes:
Qué son los modelos generativos y cómo evolucionaron.
Por qué los modelos de difusión han cambiado las reglas del juego.
Cómo se entrena una IA para revertir el ruido y crear orden desde el caos.
Qué tipos de generación existen y qué herramientas están disponibles hoy mismo.
Y hacia dónde se dirige todo esto cuando se une con modelos de lenguaje.
Esto ya no es solo tecnología. Es una nueva forma de crear.
Pero para poder usar estas herramientas con cabeza, criterio y creatividad…
hay que entenderlas desde dentro.
Ese es el objetivo de The Learning Curve.
Y si esta guía te ha ayudado, hay dos cosas que puedes hacer:
Compartirla con alguien que esté empezando o tenga curiosidad por la IA.
Apoyar esta newsletter con una suscripción de 5 $/mes. No te desbloquea contenido secreto, pero permite que pueda dedicar más tiempo a escribir cosas como esta, sin depender de patrocinadores ni fórmulas mágicas.
—Daniel
Muy buen post Daniei, gracias!
Buenísimo Daniel, muy didáctico, ¡muchas gracias! 👏